Chapitre 4 Structures et types de données
Il existe plusieurs types de données dans R, et différentes façons de les manipuler en découle. Le type de structure ou d’objet utilisé dépendra principalement de la nature de l’information à y stocker et des manipulations que l’on veut effectuer dessus. Trois principaux types de données et quatre principales structures sont utilisées régulièrement dans R.
4.1 Les types de données
Les principaux types de données sont:
- les charactères
c("character","another one")
- les doubles
c(1.5,2.248,3.01)
- les entiers
c(1,2,3)
- les booléens
c(TRUE,FALSE)
Il existe aussi d’autres types, dérivés ou non des types précédents comme les datesas.POSIXct(c("1990-01-01","2017-06-03")), les complexes, ou les “raw” (séquences de bits), qui ne seront pas discutés tout de suite.
Il est à noter qu’un manque de donnée se note généralementNA(= not applicable: non applicable) ou bienNULLpar exemple pour un vecteur ou une liste de longueur nulle (i.e. vide). Il existe un type deNApour chaque type de données :NA_character_,NA_real_,NA_integer_etNA_complex_, mais l’utilisateur n’a généralement pas en soucier, car R applique automatiquement le type deNAassocié au type de donnée.
4.1.1 Les charactères (character)
Les charactères (character) peuvent prendre n’importe quelle forme (même celle d’un chiffre), et comporter n’importe quel charactère, même un espace. Pour créer un charactère, il suffit de le déclarer entre guillemets " (ou ') comme ceci: "character". Ils peuvent être composés d’un seul charactère "a", de plusieurs "abc", ou même d’une phrase "ceci est un seul charactère". Pour créer un vecteur de plusieurs charactères, il faut utiliser la fonction c() comme nous l’avons déjà vu: c("a","b","c"). Voici un exemple incluant une déclaration et un test :
## [1] "a"## [1] TRUE4.1.2 Les doubles (double)
Les doubles sont des nombres décimaux. Ils sont le type de données que vous utiliserez probablement le plus souvent. Pour les déclarer, rien de plus simple, il suffit d’écrire votre chiffre, puis de l’utiliser comme bon vous semble. Voici un petit exemple :
## [1] 130.338## [1] TRUELes doubles ont en plus d’autres valeurs possibles qui correspondent plutôt à des erreurs de calculs ou de précision:
- le
NaN, qui signifie Not a Number (= Pas un nombre). Qui est souvent le résultat d’une opération mathématique interdite, comme un logarithme ou une racine carrée d’un nombre négatif.
- le
-Infet leInf, qui sont le résultat d’une opération mathématique qui ne peut pas être calculée car trop grande ou trop petite. Exemple :
## [1] NaN## [1] Inf## [1] -InfPour bien comprendre ce type d’erreurs, et comment ils sont utilisés par R, vous devez d’abord comprendre comment un ordinateur perçoit les doubles. Je comprends que ce type d’information puisse moins vous intéresser, mais je pense fermement que vous devez connaître ceci avant de passer à la suite. Cependant, vous pouvez sauter le paragraphe qui suit pour une première lecture, et aller directement à Les entiers (integer).
Cette partie peut vous paraître difficile et éloignée du sujet de prime abord, mais vous verrez par la suite à quel point elle peut être importante lors de certains calculs.
Si vous lisez ce livre depuis un navigateur avec une connexion internet, je vous renvoie à l’article wikipédia sur le sujet en français ou celui en anglais encore plus complet, sinon, je vais vous faire ici un petit résumé simplifié.
En informatique, un double est un type de donnée utilisé pour représenter les nombres décimaux (nombre à virgule). Comme un ordinateur utilise des suites de bits (0 ou 1) pour fonctionner, il doit représenter les nombres décimaux avec une précision donnée, c’est à dire un nombre de bits donné pour représenter un nombre. Nous les humains faisons de même. En effet, pour écrire en décimale le nombre pi, nous n’écrirons certainement pas tous les chiffres après la virgule (je vous met au défi), mais nous en feront plutôt une approximation. Parfois nous écrirons 3.14 pour aller très vite, parfois lorsque la précision s’impose nous écrirons 3.141593 (ou plus). Comme un ordinateur ne peut pas savoir à l’avance avec quelle précision nous voulons travailler, nous lui imposons une précision fixe, qui aujourd’hui est le format double précision (d’où le nom de double) 64 bits de la norme (IEEE 754). Ces nombres sont représentés grâce à trois informations: le signe du nombre s (- ou +), la mantisse m (~les chiffres du nombre) et un exposant e (entier relatif qui donne la position de la virgule dans la mantisse, ce qui donne le nom de virgule flottante). Il s’agit un peu d’un équivalent de la notation scientifique.
Un nombre peut donc être représenté comme ceci3 :
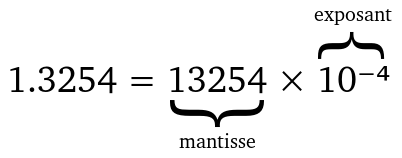
En double précision, ces trois informations ensemble ne doivent pas dépasser 64 bits. L’encodage est donc divisé comme suit:
1 bit pour le signe, 11 bits pour l’exposant et 52 bits pour la mantisse, ce qui donne 53 bits de précision, donc environ 16 chiffres significatifs. Si vous avez bien compris comment les doubles sont encodés, alors vous aurez compris que R peut donc représenter des nombres avec beaucoup de précision, mais pas avec une précision infinie.
Que vous ayez bien compris ou non, retenez ces deux conclusion:
1- La précision n’est pas infinie:
Il est important de toujours garder en tête que la précision des calculs dans R n’est pas infinie, et donc que sous certaines conditions R peut présenter un comportement non valide mathématiquement, comme par exemple lors d’une soustraction de nombres extrêmement proches de zéro comme suit :
## [1] 0Comme vous pouvez le voir R retourne 0, ce qui est faux. Un calcul de cette précision peut paraître superflu mais ce genre d’erreur peut s’accumuler de calculs en calculs et devenir bien plus grande par la suite.
Bien sûr, il est très rare d’utiliser de telles précisions, et les erreurs engendrées n’auront aucun impact réel sur vos calculs. Pour l’exemple, voici un autre calcul très précis, que R peut gérer (si votre ordinateur le permet) :
## [1] -9.881313e-324NB: pour voir quel degré de précision votre ordinateur (et R) peut gérer, vous pouvez regarder le contenu de l’objet .Machine dans la console de R.
2- La précision en informatique = chiffres significatifs
Il faut retenir que les grands nombres ont moins de chiffres après la virgule. En effet, la précision en informatique se réfère aux chiffres significatifs, c’est à dire au nombre de chiffres que comporte un nombre au total (avant ou après la virgule). Ceci est différent de la “précision décimale”, qui se réfère au nombre de chiffres après la virgule.
Comme la précision ne change pas avec le nombre considéré, plus un nombre est grand (positif ou négatif), moins on peut représenter de chiffres après sa virgule. En effet, 0.003 comporte 4 chiffres, dont 3 après la virgule. 3000 comporte 4 chiffres aussi, mais aucun après la virgule. Ils ont la même précision arithmétique au sens de chiffres significatifs (4), mais pas au sens de “précision décimale” qui donnerait 3000.0000 pour une précision de 4.
Regardez par vous même, on voit que R est capable de calculer ceci :
## [1] TRUE(a est bien différent de 0)
Mais il ne pourra pas calculer ceci :
## [1] FALSE(a est considéré égal à 1, donc la soustraction 1-10^-323 n’est même pas prise en compte)
On peu aussi noter que même si R arrive à utiliser des nombres avec de grandes précisions, celui-ci arrondi souvent le résultat lorsqu’il l’affiche dans la console. Pour voir un nombre complet, on peut utliser la fonction print() avec son argument digits, qui donne le nombre de décimale voulues, comme ceci:
## [1] 1.000000000000022Enfin, si la précision vous importe vraiment et que vous devez utiliser des chiffres plus précis que la double précision, vous pouvez jeter un oeil au package Rmpfr et le package Brobdingnag.
4.1.3 Les entiers (integer)
En informatique, les entiers sont des entiers relatifs (nombre avec signe). Pour être différenciés des doubles, les entiers (integer) sont déclarés suivis de la lettre L comme suit :
## [1] "1 24 -500"## [1] TRUE4.1.4 Les booléens (boolean or logical)
Les booléens sont des nombres logiques, aussi appelés variable d’état. Les booléens ont deux valeurs possibles uniquement, TRUE (vrai) et FALSE (faux).
Dans R T est un raccourci pour TRUE, et F un raccourci pour FALSE.
Voici comment déclarer et tester un booléen :
a= TRUE
b= T # équivalent de a
c= FALSE
d= F # équivalent de c
is.logical(a) # teste si a est un booléen## [1] TRUE4.1.5 En bonus, les facteurs (factors)
Les facteurs sont un type de données un peu spéciaux. Ils permettent d’utiliser des catégories de données dans une même variable. On peut prendre l’exemple d’une personne qui regarde de quelle couleur sont les voitures qui passent devant son entrée, s’il relève 3 voitures rouges, deux bleues et quatre blanches, alors on peut dire que nous avons trois catégories de couleurs de voitures: rouge, bleue, blanche. Pour déclarer ceci dans R, nous ferions comme suit :
couleurs= factor(c("rouge","rouge","rouge","bleue","bleue","blanche",
"blanche","blanche","blanche"))
couleurs # nous avons un vecteur de charactères, et R reconnait automatiquement les 3 catégories (levels) ## [1] rouge rouge rouge bleue bleue blanche blanche blanche blanche
## Levels: blanche bleue rougeOn voit que couleurs se présente comme un vecteur, mais contient un métadonnée de plus, les levels, qui résument les valeurs uniques du vecteur, et donc qui décrivent les différentes valeurs possible du vecteur.
La fonction level permet de retrouver les catégories :
## [1] "blanche" "bleue" "rouge"Les facteurs sont souvent utilisés dans d’autres fonctions comme pour les graphiques ou les modèles. En général, il est préférable d’éviter leur utilisation et de les remplacer par un autre type de donnée, à moins d’en avoir un réel besoin.
4.2 Les transformations
R est un language extrèmement maléable, si bien qu’il existe des “ponts” entre les types de données. On pourra donc très facilement transformer un type de données en un autre dans certains cas.
- integer vers double :
il s’agit de la transformation la plus facile. R ne requiert aucun préalable à cette transformation, si bien que celle-ci se fait sans même y réfléchir:
## [1] TRUE## [1] "numeric" "vector"- double to integer :
L’inverse n’est pas aussi simple et doit se faire en utilisant une fonction deRsemblable à la fonction de test (is.integer) que nous avons déjà vu :as.integer. En voici un exemple :
## [1] TRUEb= as.integer(a) # on force a à devenir un entier
b # b est maintenant un integer (R à tronqué le chiffre)## [1] 2 2 3- double (ou integer) to character :
Cette transformation est aussi assez simple et peut se faire en utilisant la fonctionas.character:
## [1] TRUE## [1] "2" "2.5" "3.8"b est maintenant un charactère (notez les guillemets qui entourent chaque chiffre)
- character to double (ou integer) :
Comme vous l’avez deviné, cette transformation peut se faire grâce à la fonctionas.double. Cependant, il faut être très prudent lorsque l’on fait une transformation dans ce sens, car R peut parfois présenter des comportements inattendus.
a= c("1","2","3") # a est déclaré comme un vecteur de 3 charactères
is.character(a) # a est bien considéré comme un charactère## [1] TRUE## [1] 1 2 3Maintenant un exemple avec des facteurs, qui peuvent donner des résultats inattendus lorsqu’ils sont composés de charactères comportant des chiffres et des lettres :
a= factor(c("1","a","3")) # a est déclaré comme un facteur de logueur 3
b= as.numeric(a) # on force a à devenir un double
b # b est bien un double, mais le résultat est quelque peu déroutant## [1] 1 3 2## [1] "numeric" "vector"Comme on peut le voir, la transformation est déroutante : le “3” du facteur est devenu un 2, et le “a” un 3. Pour comprendre ce qu’il s’est passé, il faut savoir que pour transformer un facteur en numérique, R prends les catégories comme des charactères, puis les trie alphanumériquement (i.e. de 0 à 9 puis de A à Z), puis alloue l’index de chaque catégorie comme nouvelle valeur. Donc ici R à décidé de l’ordre suivant dans les catégories : “1”<“3”<“a”, puis leur à alloué un index : “1”=1, “3”=2, “a”=3, et a remplacé les valeurs de chaque catégorie par son index pour que “1”,“a”,“3” devienne 1,3,2. Ce type d’erreur peut être évité en utilisant la combinaison de fonctions suivantes :
a= factor(c("1","a","3")) # a est déclaré comme un facteur de longueur 3
b= as.numeric(levels(a))[a] # on force a à devenir un double## Warning: NAs introduits lors de la conversion automatique## [1] 1 NA 3b est bien un double, le résultat est bon, et le charactère “a” est transformé en NA.
Maintenant que vous connaissez mieux les charactères, les doubles, les entiers, et les booléens, vous allez voir comment les organiser dans des structures de données qui vous permettront de les stocker dans des objets plus ou moins complexes.
4.3 Les Structures de données
R met à disposition de ses utilisateurs quatre grands types de structures de données plus ou moins liées: les vecteurs, les matrices, les tableaux et les listes.
4.3.1 Vecteurs
Nous avons déjà vu un premier exemple de vecteurs dans le chapitre précédent (Premiers pas), qui introduisait la fabrication d’un vecteur contenant des chiffres.
Les vecteurs sont une structure de données à une dimension, c’est à dire qu’il s’agit d’une suite de données rangées en “ligne”. Un vecteur ne peut contenir qu’un seul type de données à la fois (charactère, booléen…). Si l’on construit un vecteur avec plusieurs types de données consécutifs, ils sont alors transformés de la même façon que nous avons vu les tranformations précédement dans Les transformations. Il est à retenir que R essaye toujours de prendre le types de donnée qui gardera le plus d’information. Par exemple un mélange de charactères et de doubles sera transformé en charactère pour ne pas perdre l’information des charactères (qui seraient transformés en NA autrement).
Il existe plusieurs moyens de créer un vecteur. Tous ont un avantage associé, et seront utilisés en fonction du contexte:
- En utilisant as.vector pour créer un vecteur de la taille désirée, que l’on remplira par la suite. Comme les vecteurs ne peuvent contenir qu’un seul type de données, il faut déclarer le type dès la création grâce à l’argument “mode”. Les différents modes sont
logical(= booléen),integer(= entier),numeric(= double),complex(= complexe),character(= charactère) andraw(= bits). Voici un exemple de vecteur numérique:
## [1] 0 0 0 0 0 0 0 0 0 0- En utilisant la fonction
c(), qui concatène ses arguments :
## [1] 1 10 8- En utilisant d’autres fonction comme
seq(),rep(),:etc… :
4.3.2 Matrices
Une matrice est très semblable à un vecteur, sauf qu’elle comporte deux dimensions, il s’agit là d’une matrice dans son sens mathématique. Comme les vecteurs, les matrices ne peuvent contenir qu’un seul type de données. Voici un exemple de création de matrice:
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9La fonction matrix est très utile car on peut choisir le nombre de lignes et/ou de colonnes, ainsi que le sens de remplissage des données avec l’argument by.row. La fonction matrix est un très bon utilitaire pour construire des structures 2D vides notemment, comme suit:
## [,1] [,2]
## [1,] NA NA
## [2,] NA NA
## [3,] NA NA
## [4,] NA NA
## [5,] NA NA
## [6,] NA NA
## [7,] NA NA
## [8,] NA NAUne matrice peut aussi comporter une seule colonne, ou une seule ligne.
4.3.3 Tableaux
Il existe deux types de tableaux dans R: array et data.frame.
Le premier est rarement utilisé. Il s’agit ni plus ni moins d’un vecteur à n dimensions (englobe donc vecteur et matrices).
## [1] 1 2 3 4 5 6 7 8 9## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9## , , 1
##
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9Le second, le data.frame, est peut-être la structure la plus utilisée dans R. Cette structure représente le sens commun que l’on se fait d’un tableau. Structurellement, le data.frame se présente donc comme un tableau comportant un nombre défini de colonnes et de lignes. Chaque colonne comporte le même nombre de lignes. Dans R, un data.frame est une liste de vecteurs de même longueur. Le plus grand avantage du data.frame est que chaque colonne peut contenir un type de donnée différent.
## a b
## 1 Jour 1 40
## 2 Jour 2 50
## 3 Jour 3 45Les data.frame sont utilisés par la grande majorité des fonctions dans R.
4.3.4 Listes
Les listes (list) sont aussi un type de structure très important dans R. Il faut penser la liste comme étant au data.frame ce qu’est l’array à la matrice. Il s’agit d’un data.frame de dimension n.
On peut mettre n’importe quel type de données de n’importe quelle taille dans une liste, même une autre liste (= nested list).
## $a
## [1] "Jour 1" "Jour 2" "Jour 3"
##
## $b
## [1] 40 50 45
##
## $c
## [1] 1
##
## $d
## $d[[1]]
## [1] 1 2 3
##
## $d[[2]]
## [1] 8 7 6 5 4
##
## $d[[3]]
## [1] "a"Les listes sont un peu complexe à appréhender mais sont certainement le type de structure le plus maléable, et finalement le plus simple à travailler.
Il est à noter que le data.frame est en fait une liste de vecteurs. On peut donc remplir l’une de ses colonnes par une liste, mais ce type d’utilisation est plutôt déconseillé dans un premier temps car il limite l’utilisation de fonctions spéciales adaptées aux data.frame, mais aussi à celles adaptées aux listes.
4.3.5 Attributs
Il est possible d’associer n’importe quelle métadonnée à un objet dans R. Ces métadonnées sont appelés attributs. Ces attributs n’ont aucune influence sur la valeur de la donnée elle-même, mais elle peut apporter des informations complémentaires à l’utilisateur ou à une fonction.
Voici un exemple d’attribut qui permet à l’utilisateur de se rappeler l’unité d’un objet:
Certains attributs sont utilisés par des fonctions. C’est le cas du nom et de la dimension d’un objet.
Voici un exemple de la hauteur de 10 arbres dans une forêt:
Cette hauteur n’a pas de nom (names() retourne NULL):
## NULLOn peut assigner un nom comme suit:
## [1] "arbre_1" "arbre_2" "arbre_3" "arbre_4" "arbre_5" "arbre_6" "arbre_7" "arbre_8"
## [9] "arbre_9" "arbre_10"On peut aussi retrouver le nom de chaque valeur grâce à la fonction attributes():
## $names
## [1] "arbre_1" "arbre_2" "arbre_3" "arbre_4" "arbre_5" "arbre_6" "arbre_7" "arbre_8"
## [9] "arbre_9" "arbre_10"Idem pour la dimension d’une matrice avec dim(). On crée une matrice de dimension 2,3:
## Warning in matrix(1:8, 2, 3): la longueur des données [8] n'est pas un diviseur ni un
## multiple du nombre de colonnes [3]## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6Sa dimension est 2,3:
## [1] 2 3On peut la modifier comme ceci:
## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6Ou en utilisant la fonction attr():
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6Les fonctions names() et dim() sont en fait des raccourcis pour attr(matrice,"names") et attr(matrice,"dim") respectivement.
4.4 Manipuler les structures
La manipulation des structures se fait en accord avec les spécificités de chacunes.
4.4.1 Index et Test
La manipulation la plus courante est l’indexage. En d’autres termes, il s’agit là de récupérer les valeurs d’une structure en fonction de sa position, de son nom ou d’une condition.
L’index se fait le plus souvent en utilisant la fonction [, appelée fonction extract. Par exemple, pour récupérer la troisième valeur d’un vecteur, on utilisera la fonction comme suit: a[3]. Il est à noter que l’indexage se fait à partir de 1, car la première valeur du vecteur est en position 1. Cela peut porter à confusion pour les utilisateurs venant d’autres languages de programmation tels que Python, qui indexe à partir de 0. Une autre particularité de R est l’utilisation du - comme un sauf. Donc a[-3] récupèrera le vecteur a sauf sa troisième valeur. Lorsque l’on a plus d’une dimension (e.g. matrice ou data.frame), on sépare l’index de chaque dimension par une virgule (e.g. [ligne,colonne]). Pour récupérer les objets d’une liste, on utilisera la fonction [[. On peut aussi indexer un vecteur par le nom de son objet comme suit a["nom de l'objet"] mais aussi en testant une condition comme ceci a[c(T,T,F)].
Une deuxième fonction que l’on peut utiliser pour le data.frame et la list est la fonction $. Celle-ci indexe les colonnes du premier et les objets du second par leur nom.
- Vecteur
a= c(10:15) # a est un vecteur numérique de 10 à 20.
a[3] # on veut récupérer la troisième valeur du vecteur a## [1] 12## [1] 10 14 12## [1] 11 12 13 14 15a[c(T,F,F,T,T)] # on veut récupérer toutes les valeurs de a sauf la 2e et 3e valeur qui sont refusées par le FALSE (F).## [1] 10 13 14 15- matrice:
## [1] 12 15 18 21## [1] 10 12## [,1] [,2] [,3]
## [1,] 11 17 20
## [2,] 12 18 21- data.frame
a= data.frame(Num= c(1:10), Prix= c(11:20)) # a est un data.frame
a[3,] # comme sur les matrices, on veut récupérer la troisième ligne entière## Num Prix
## 3 3 13## [1] 1 3## [1] 2 3 4 5 6 7 8 9 10## [1] 11 12 13 14 15 16 17 18 19 20## Num
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 10- liste
a= list(Num= c(1:3), Prix= c(11:13), Id_et_serie= list(Id= c(1,1,1), serie= c(2,2,2)), Classe= data.frame(a=1:3,b=1:3)) # a est un data.frame
a[1:2] # on veut récupérer une liste des 1er et 2nd objets de la liste## $Num
## [1] 1 2 3
##
## $Prix
## [1] 11 12 13## [1] 1 2 3## $Prix
## [1] 11 12 13
##
## $Id_et_serie
## $Id_et_serie$Id
## [1] 1 1 1
##
## $Id_et_serie$serie
## [1] 2 2 2
##
##
## $Classe
## a b
## 1 1 1
## 2 2 2
## 3 3 3a[[3]][1] # on veut récupérer les valeurs du premier objet de la liste en 3e position de la liste a.## $Id
## [1] 1 1 1a[[4]][,1] # on veut récupérer les valeurs de la 1e colonne du data.frame en 4e position de la liste a.## [1] 1 2 3## [1] 1 2 3## [1] 11 12 13a$Id_et_serie$serie # on veut récupérer les valeurs de l'objet nommé serie dans l'objet nommé Id_et_serie## [1] 2 2 2## $Num
## [1] 1 2 3
##
## $Classe
## a b
## 1 1 1
## 2 2 2
## 3 3 3Donc pour résumer, l’indexage commence à 1, et l’index se fait comme suit: vecteurs [i], matrices/tableaux [i,j] et listes [[i,j]] ou [1] ou [[1]] Pour indexer plusieurs éléments:
- selon numéro de l’index lignes/colonnes [1:10], [,1:10]
- selon condition test [c(T,T,F,T)]
4.4.2 Remplacer, assigner
Il est possible de remplacer des valeurs dans une structure en spécifiant l’index de la valeur à remplacer et lui ré-assignant une nouvelle valeur :
## [1] 12On remplace sa valeur par 5:
## [1] 10 11 5 13 14 15Attention, si on remplace une valeur par un autre type de données, cela peut changer le type de tout le vecteur:
## [1] "a" "11" "5" "13" "14" "15"On peut aussi modifier plusieurs valeurs à la fois:
## [1] "5" "5" "5" "13" "14" "15"4.4.3 Concaténation
On peut aussi concaténer les différentes structures de données:
- vecteur, en utilisant la fonction
c():
## [1] 1 2 3 4 5 6 7 8 9 10 2 8- matrice/data.frame en utilisant
rbindpour concatener par lignes,cbindpour concatener par colonnes :
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 1 4 7 10 13 16
## [2,] 2 5 8 11 14 17
## [3,] 3 6 9 12 15 18## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9
## [4,] 10 13 16
## [5,] 11 14 17
## [6,] 12 15 184.4.4 Transformation
On peut transformer des structures simples très facilement dan R, comme passer d’un charactère à un numérique par exemple (voir [transform_datatype]), mais aussi pour des structures plus complexes, comme les matrices, les tableaux et les listes. Les structures ont très souvent une fonction associée pour passer de l’une vers l’autre.
Par exemple pour transformer quelque chose en matrice, on utilisera as.matrix, as.data.frame pour les tableaux, as.vector pour les vecteurs, ou encore as.list pour les listes. Bien sûr l’utilisateur doit s’efforcer de présenter les données de façons structurées pour que ces fonctions puissent effectuer la transformation.
Une liste pourra par exemple être tranformée en data.frame seulement si son contenu est de même longueur:
## a b
## 1 1 3
## 2 2 4Ici le data.frame est bien crée car a et b dans liste ont la même longueur. Par contre si b était plus long, la fonction as.data.frame ne sait pas a priori ce qu’elle doit faire, donc elle retourne une erreur.
4.4.5 Transposition
Une matrice peut être transposée grâce à la fonction t() comme suit:
## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9On peut aussi transposer un data.frame avec t(), mais celui-ci est alors transformé en matrice:
## [,1] [,2] [,3]
## V1 1 2 3
## V2 4 5 6
## V3 7 8 9La transformation en matrice peut être un problème si l’on utilise des colonnes de types différent, car la fonction va uniformiser le type des données:
## [,1] [,2]
## a "1" "2"
## b "1" "2"Ici toutes les données sont transformées en charactère.
4.4.6 Opérations
Il est très simple d’appliquer des opérations mathématiques sur des structures dans R car ces fonctions sont vectorisées, c’est à dire que les fonctions +, -, *, /,… peuvent s’appliquer à plusieurs valeurs d’un seul coup. Par exemple on peut multiplier un vecteur par un autre comme ceci:
## [1] 6 14 24 36 50On peut aussi multiplier des colonnes de data.frame:
## [1] 6 14 24 36 50Pour plus de détails, voir le chapitre “[datascience1]”.
{kind=link}